Reprocess & Reclassify Torrents
The classifier is being updated regularly, and to reclassify already-crawled torrents you’ll need to “reprocess” them.
For context: after torrents are crawled or imported, they won’t show up in the UI straight away. They must first be “processed” by the job queue. This involves a few steps:
- The classifier attempts to classify the torrent (determine its content type, and match it to a known piece of content)
- The search index for the torrent is built
- (In future there’s likely to be other steps here, such as running rule-based actions)
- The torrent content record is saved to the database
Reprocess individual torrents
Individual torrents can be reprocessed from the “Classification” tab of the torrent detail view.
The following options are available:
- Match content by local search: Enables a local search query on the content table for matching torrents to known content. This should be tried before any external API call is attempted, but it’s an expensive query and so it’s useful to be able to disable it using this flag.
- Match content by external API search: Enable API calls during classification. This makes the classifier run a lot slower, but enables identification with external services such as TMDB. Metadata already gathered from external APIs is not lost, hence this option is disabled by default.
- Force rematch of already matched content: Ignores any pre-existing match and always classifies from scratch (A torrent is “matched” if it’s associated with a specific piece of content from one of the API integrations, currently only TMDB)
Enqueue torrent processing batch
From within the admin dashboard of the web UI, the “Enqueue torrent processing batch” dialog allows you to re-queue torrents and apply the latest classifier updates to their content records.
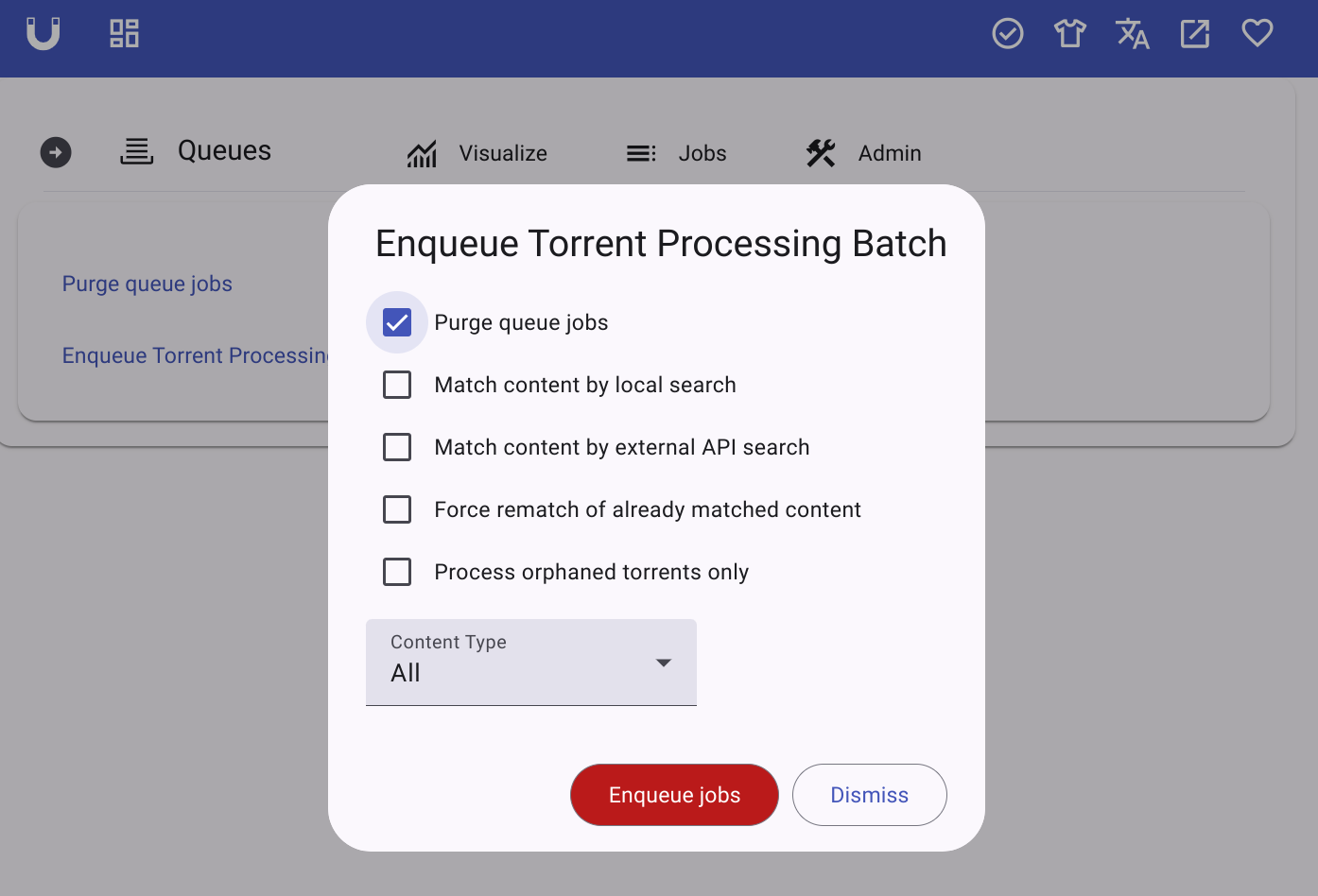
The following options are available:
- Purge queue jobs: This will remove any existing jobs from the queue, and is recommended when queueing a full reprocess.
- Match content by local search: Enables a local search query on the content table for matching torrents to known content. This should be tried before any external API call is attempted, but it’s an expensive query and so it’s useful to be able to disable it using this flag.
- Match content by external API search: Enable API calls during classification. This makes the classifier run a lot slower, but enables identification with external services such as TMDB. Metadata already gathered from external APIs is not lost, hence this option is disabled by default.
- Force rematch of already matched content: Ignores any pre-existing match and always classifies from scratch (A torrent is “matched” if it’s associated with a specific piece of content from one of the API integrations, currently only TMDB)
- Process orphaned torrents only: Only reprocess torrents that have no content record.
- Content types: Only reprocess torrents that are currently under the specified content types.