Frequently Asked Questions
Does bitmagnet download or distribute any illegal or copyright-infringing content?
No. bitmagnet does not download, store or distribute any content at all. It only downloads metadata about content. It may download metadata about illegal or copyright infringing content, and users should therefore exercise discretion in any magnet links they add to their BitTorrent client. bitmagnet attempts to detect and filter harmful content such as CSAM to avoid users having such undesirable metadata in their index.
Should I use a VPN with bitmagnet?
It is recommended to use a VPN: bitmagnet may download metadata about illegal and copyrighted content. It is possible that rudimentary law enforcement and anti-piracy tracking tools would incorrectly flag this activity, although we’ve never heard about anyone getting into trouble for using this or similar metadata crawlers. Setting up a VPN is simple and cheap, and it’s better to be safe than sorry. We are not affiliated with any VPN providers, but if you’re unsure which provider to choose, we can recommend Mullvad and ProtonVPN.
Is bitmagnet intended to be used as a public service?
No, it was designed to be self-hosted. The UI and API allow destructive actions, and no security or scalability review has taken place, so it’s not advised. An API is exposed, that could in theory be used to build a public service, but it’s not going to be the focus of this project to support that use case.
What are the system requirements for bitmagnet?
As a rough guide, you should allow around 300MB RAM for BitMagnet, and at least 1GB RAM for the Postgres database. You should allow roughly 80GB of disk space per 10 million torrents, which should suffice for several months of crawling, however there is no upper limit to how many torrents might ultimately be crawled. The database will run fastest when it has plenty of RAM and a fast disk, preferably a SSD.
I’ve started bitmagnet for the first time and am not seeing torrents right away, is something wrong?
If everything is working, bitmagnet should begin showing torrents in the web UI within a maximum of 10 minutes (which is its cache TTL). The refresh button at the top of the torrent listing is a cache buster - use it to see new torrent content in real time. Bear in mind that when a torrent is inserted into the database, a background queue job must run before it will become available in the UI. If you’re importing thousands or millions of torrents, it might therefore take a while for everything to show. Check the next question if you’re still not seeing torrents.
bitmagnet isn’t finding any new torrents, what’s wrong?
Important
bitmagnet is known to work well on Linux and MacOS; if it isn’t finding new torrents when running on these platforms, this is probably due to a misconfiguration, rather than a bug in the software.
Note that some Windows users have reported issues: if you are having issues on Windows, then for now it’s advisable to run the software on Linux or MacOS instead.
bitmagnet now shows its health status in the main toolbar: It will show a tick for health, a cross for unhealthy or sometimes 3 dots for pending. Click on it to open the health dialog and check that all workers are running and healthy.
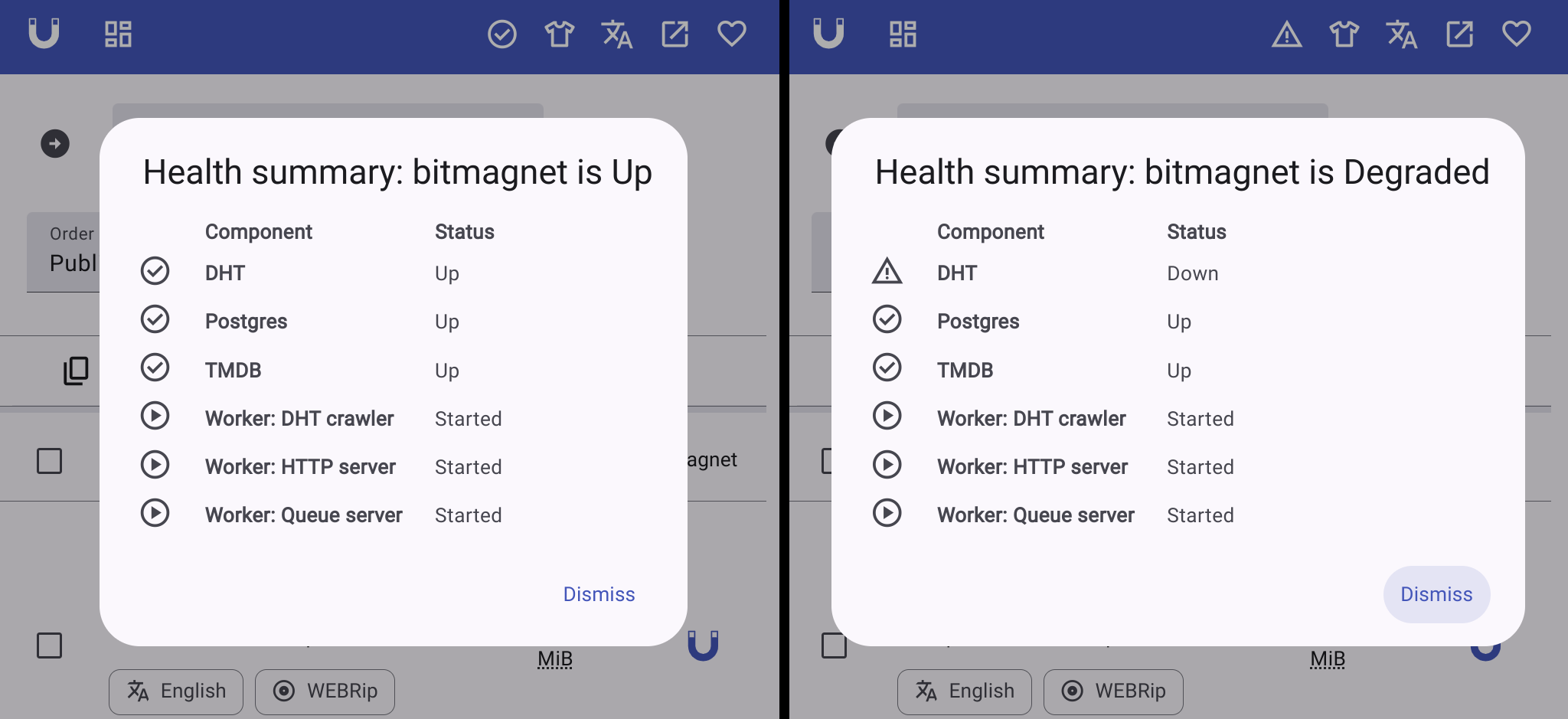
The most common issues are networking, firewall or a VPN misconfigurations preventing bitmagnet from connecting to the DHT. Additionally, the TMDB API is blocked in certain countries; if you are in an affected country you may need to either disable the TMDB integration with the tmdb.enabled configuration key, or use a VPN. Configuring a personal TMDB API key (or disabling TMDB) will make the queue run a lot faster.
The dashboard can be used to monitor queue throughput. On the queues dashboard, the following would indicate a problem:
- A high number of pending jobs, and the number of processed jobs not increasing over time
- A high number of failed jobs
- No new jobs being created over time
Why doesn’t bitmagnet show me exactly how many torrents it has indexed?
Torrents are indexed to a Postgres database, and Postgres is notoriously slow in counting large numbers of rows. To provide acceptable performance, bitmagnet uses a strategy it calls a “budgeted count”. This takes advantage of the fact that the Postgres query planner can provide an estimated count, along with the total cost of executing the count query. If the cost exceeds the budget, we return the estimate, and the UI will show an estimate symbol ~. If the cost is within budget, we return the exact count. For large result sets, you will probably always be seeing an estimate.
At what rate will bitmagnet crawl torrents from the DHT?
This will depend on a number of factors, including your hardware and network conditions, and your dht_crawler.scaling_factor configuration. Typically it can be anything from 100 to 1,000 torrents per minute. Crawling is likely to slow down as your index grows larger, as it’s more likely that any discovered torrent will already be in your index.
How can I see exactly how many torrents bitmagnet has crawled in the current session?
The new dashboard shows throughput of the crawler and job queue. Alternatively, visit the metrics endpoint at /metrics and check the metric bitmagnet_dht_crawler_persisted_total. {entity="Torrent"} corresponds to newly crawled torrents, and {entity="TorrentsTorrentSource"} corresponds to torrents that were rediscovered and had their seeders/leechers count, and last-seen-on date updated.
How are the seeders/leechers numbers determined for torrents crawled from the DHT?
The DHT crawler uses a BEP33 scrape request to provide a very rough estimate of the current seeders/leechers.
How do I know if a torrent crawled by bitmagnet is being actively seeded, and that I’ll be able to download it?
The short answer is you can’t. The only way to know for sure is to add an info hash to your BitTorrent client. The seeders/leechers count provides an imperfect indicator of the torrent’s health. In future bitmagnet may provide “decentralized tracker”-like features that would improve this.
Can I ask bitmagnet’s DHT crawler to crawl specific hashes?
No. The DHT crawler works by sampling random info hashes from the network, and was not designed to locate specific hashes - it only crawls what it finds by chance. You can use the import the /import endpoint to import specific torrents, and additional methods (separate from the DHT crawler) may be added in future.
I’m seeing a lot of torrents in the “Unknown” category, that are clearly of a particular content type - what’s wrong?
bitmagnet is in early development, and improving the classifier will be an ongoing effort. When new versions are released, you can follow the reclassify turorial to reclassify torrents. If you’d like to improve or customize the classifier, this is also possible.
How can I make bitmagnet automatically delete torrents I’m not interested in?
A better question would be: why bother? Disk space is inexpensive in the quantities required by bitmagnet, and searching is easier than deleting. Nevertheless this is one of the most commonly asked questions, and it is possible to do this by customizing the classifier. Please consider the wastage of resources and load on the network created by deleting what you’ve crawled. Also remember that the classifier isn’t perfect: for example, enabling deletion of XXX content will also delete anything that has been mis-identified as XXX by the classifier, preventing you from finding it in future - for example because it contains a rude word. If you are deleting a large proportion of what you’re crawling, you are almost certainly deleting over-zealously and you should consider just using one of the many indexer sites instead.
Can I run multiple bitmagnet instances pointing to the same database?
Yes you can, just point multiple instances to one database and it will work - but it will put more load on the database and cause the app to run slower. An alternative is to run multiple instances with multiple databases, and periodically merge the databases.